
According to Open Web Application Security Project (OWASP) ratings of top cybersecurity risks, among which web application risks, mobile and IoT devices risks, machine learning systems vulnerabilities, the problem of protection in the digital space continues to be extremely relevant. Here we will consider actual challenges which are arising from the conjunction of machine learning and cybersecurity applications in different areas such as IoT ecosystems, targeted advanced persistent threats, fraud and anomalies detection, etc. Also, you will find interesting ideas for your future machine learning projects.

Internet of Things (IoT) systems
Due to the computational resources constraints of IoT devices and its insecure authorization/network protocols, the problem of its protection is currently acute. Different layers of IoT ecosystem should be protected: Perception Layer, Network Layer and Application Layer. Therefore, researchers are considering using machine learning algorithms to monitor network traffic; defend against botneck attacks, ransomwares, crypto-jacking, advanced persistent threats (APT), distributed-denial-of-service (DDoS) and man-in-the-middle (MITM) attacks; provide IoT applications security, etc.
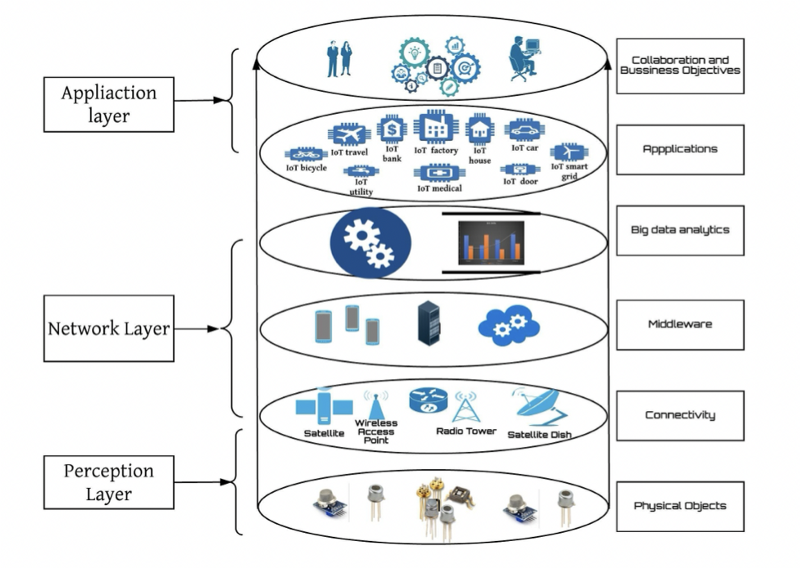
IoT Architecture, source: “A Survey of Machine and Deep Learning Methods for Internet of Things (IoT) Security”
Despite the success of ML algorithms application in other fields, in the field of IoT layers security, there are still some challenges and problems to be solved. One such problem is the lack of data or lack of high-quality data. For example, to evaluate ML approach to protect from botnet attacks, researchers are attempting to get data by infecting IoT devices with widely known Mirai and BASHLITE like it shown in “N-BaIoT: Network-based Detection of IoT Botnet Attacks Using Deep Autoencoders”. Some authors have made an attempt to simulate artificial data by using Cooja IoT simulator, while others have used testbeds to simulate different kinds of attacks.
Another one challenge is related to computational resources and energy efficiency constraints of IoT devices that can be considered as crucial bottlenecks for deep learning models deployment and usage at the edge. However, there are some techniques to reduce model size and complexity, such as quantization, pruning, knowledge distillation, network architecture search. Also, IoT environment is dynamic and it’s very important to develop a continuous training pipeline.
Let us imagine that we have successfully deployed ML model within IoT ecosystem. Here, the problem of data and ML model security is appearing. Recent advances in ML algorithms have enabled them to be used in breaking cryptographic implementations, for example, RNN model can learn patterns to break Enigma machine decryption function. Another problem is the data (user data, datasets, ML model artifacts) leakage/privacy, if attacker would know structure of the data/ML model and would have access to it, he will have a possibility for data/model poisoning, ML model fooling by generating adversarial samples and etc.
Open datasets:
- The Bot IoT Dataset
- N-BaIoT Dataset to Detect IoT Botnet Attacks
- IOT Botnets Attack Detection Dataset
- DDoS Botnet Attack
- Edge-IIoT Set
- UNSW-NB 15 dataset
- MQTT-set
ML projects ideas:
- generation/augmention existing IoT data using General Adversarial Networks (GAN) or any other generative model;
- noise reduction in IoT data using Denoising Autoencoder (DAE) models;
- network traffic anomalies detection/time series forecasting;
- IoT benign/malware applications classification and categorization;
- experimenting with quantization/pruning/knowledge distillation to optimize model for deployment purpose.
Advanced Persistent Threats (APT)
An advanced persistent threat (APT) can be defined as a targeted cyber attack which can bypass all kinds of security software (firewalls, antiviruses) and remain invisible for quite a long period of time. Among the well-known examples of such attacks is Stuxnet, which targeted SCADA (Supervisory Control and Data Acquisition) systems to cause substantial damage in the nuclear program of Iran. Epic Turla, which was identified by Kaspersky, aimed to infect the systems of government agencies, state departments, military agencies and embassies in more than 40 countries worldwide. Deep panda which was an attack carried out to obtain the staff information of the US Intelligence Service, and was probably of Chinese origin.
Techniques which are used to bypass security are exploitation of well-known vulnerabilities, malware usage, spear phishing, zero day vulnerability, watering hole attack, social engineering. A good practice to protect against such kind of attacks would be joint usage of ELK (Elasticsearch, Logstash, Kibana) stack to monitor any system anomalies and ML techniques. Due to the time-stretched and complex nature of APT attacks, in most cases it is not enough to use only machine learning protection module; such a model works in conjunction with other protection methods like signature-based methods.
As time-spread APT nature, many researchers in this field try to build solutions based on recurrent neural network (RNN) models which are aimed to process sequences. For instance, in “Advance persistent threat detection using long short term memory (LSTM) neural networks” paper, authors used LSTM model that takes Splunk SIEM event logs as input to detect APT espionage. Another approach is to construct multi-module systems like in “Detection of advanced persistent threat using machine-learning correlation analysis” to detect multi-stage APT malwares by using ML and correlation analysis. The novelty of this research lies in the detection of APT across all life cycle phases. In “A context-based detection framework for advanced persistent threats” authors used events from different sources, i.e. VPN logs, firewall logs, IDS logs, authentication logs, system event logs which were passed as data source to the detection engine. From these logs, the context of attack is identified using correlation rules. The suspicious activities are identified by matching the attack contexts using a signature database. As you can see, researchers approach the problem from different angles, and there is still plenty of room for creativity.
Open datasets:
- Dataset for a Apt Identification Triage System
- APT Malware Dataset Containing over 3,500 State-Sponsored Malware Samples
- APT-EXE, APT-DLL, APT-IoC
- NSL-KDD dataset
- Advanced Persistent Threat (APT) Malware Dataset — 2020
ML projects ideas:
- APT data simulation/generation;
- development of Intrusion Detection System (IDS) for APT detection;
- classification of APT malwares/normal malwares;
- network traffic clusterization to detect hidden patterns.
Fraud detection
The concept of fraud in the light of information security is quite extensive and affects various areas such as financial institutions, retail, logistic organizations, insurance companies, gaming/gambling, healthcare sector, social communities, governances and etc. Fraudsters try to get personal data, for which they build multi-vector attacks that may include: social engineering methods (e.g., spear phishing), malwares, account takeover scams, impersonation fraud. Recent examples of multi-vector fraud attacks include cyber attacks using the SWIFT-related banking infrastructure, ATM infections, remote banking systems and point-of-sale (POS) terminal networks, making changes in Payment Service Provider (PSP) databases to “play” with account balances, as well as the so-called supply-chain attacks. Digitization and automation of customer experience not only improve good customers outcomes, but also open the doors for fraudulent activities automatization (bot attacks): spam registrations, automation of logins for account takeover, automated testing stolen credit card credentials.
In case of supervised machine learning (kNN, logistic regression, SVM, random forests and gradient boosting, feed-forward neural networks, recurrent and convolutional neural networks, SOTA solutions which combine different deep learning models, e.g. autoencoder plus LSTM), the problem of fraud detection is usually considered as a binary classification problem of fraudulent/legitimate data samples. However, labeled data is not always available, and researchers resort to unsupervised machine learning to solve anomaly/novelty detection (Local Outlier Factor, iForest, One-Class SVM, One-class GAN, Variational AutoEncoder).
Challenges which are rising in fraud detection area using ML:
- Unbalanced data. Fraudulent samples are rare in comparison to legitimate traffic, two naive methods to overcome this problem is to use undersampling/oversampling technique, another one is Synthetic Minority Oversampling Technique strategy (SMOTE). It’s also possible to use generative models to sample new points from probabilistic distribution of fraud samples.
- Data shift. Fraudsters behaviour is dynamic, and evolve over time, as well as customers behaviour patterns. Usually training ML models on train set, we assume that it is valid on the test set (if we did everything right), but in case of data drift the hypothesis will be broken.
- Fairness of ML model is highly important. Developed ML model should treat customers diversity equally, that is before deployment into production, one should evaluate models across different customer groups. You can use TFX (TensorFlow Extended) framework which is good for all stages of driven ML model into production. This framework provides service for fairness estimation.
- High presence of categorical variables. Most learning algorithms can not handle categorical variables with a large number of levels directly, that is why optimal feature encoding strategy should be used to minimize RAM usage. Different supervised (generalized linear mixed model encoder, James-Stein estimator, target encoding, quantile encoder) and unsupervised (hashing, one-hot, count, Helmet coding) methods for categorical features encoding can be used.
- Non-linear anomalies behaviour. After model was deployed into production, the ML engineer work is not finished yet. It’s necessary to continuously monitor data, for example, you can use Kibana dashboards from ELK stack. There should be chosen optimal time frame length and schedule to retrain your model on new upcoming data to prevent data/concept drift. For instance, model retraining can happen automatically according to schedule using AirFlow framework.
- Trade-off between fraudsters stopping and making friction for legitimate users. There should be optimal trade-off threshold which will minimize False Positives (legitimate user detected as fraudster) and maximize False Negatives (fraudster detected as legitimate user) triggerings of ML model.
Open datasets:
- Credit card fraud detection Challenge
- German Credit card Fraud Data
- IEEE-CIS Fraud Detection
- Ethereum Fraud Detection Dataset
- Digital Advertising Fraud
- Job Fraud Dataset
ML projects ideas:
- experiments with different generative models for fraud samples generation;
- classification of fraudulent/legitimate activities;
- use Graph neural networks to create Anti-Money Laundering model;
- phishing URL detection;
- detection of fake accounts in social networks.
Targeted ransomwares
Malware is harmful software that comes in various forms such as viruses, worms, rootkits, spyware, trojans, ransomware, and so on. Ransomware is a type of malware that encrypts all of a user’s important files and demands a ransom to unlock them. In general, the ransom is requested in digital currency, and the anonymity of digital currency allows attackers to avoid prosecution. It also provides justification for an increase in the amount of ransomware attacks. There are two types of ransomware: crypto ransomware and locker ransomware. Crypto malware encrypts system files, rendering them inaccessible. File-Locker ransomware is another name for crypto ransomware. Locker ransomware does not corrupt data; instead, it inhibits victims from accessing their systems by displaying a window that never closes or locking their desktop. The functioning of ransomware is similar to that of benign software in that it operates without anybody being aware of it. As a result, detection of ransomware in zero-day attacks is critical at this time.
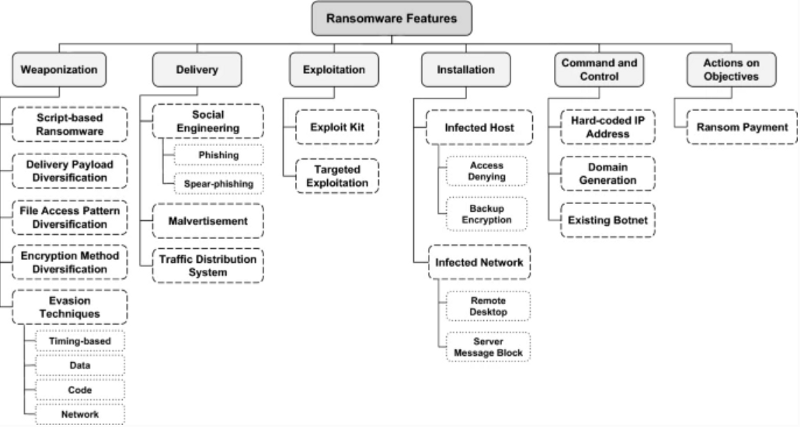
Cyber kill chain based taxonomy diagram of the ransomware features, source: “A Cyber-Kill-Chain based taxonomy of crypto-ransomware features”
There are several approaches and procedures for detecting ransomware. Static analysis based methods disassemble source code without executing it. However, they have a significant false positive rate and are incapable of detecting obfuscated ransomware. To combat these challenges, researchers are turning to dynamic behavior analysis-based tools that monitor the interactions of the executed code in a virtual environment and extract executed API sequences. However, these detection methods are slower and demand a lot of memory. Machine learning is ideally suited for analyzing the behavior of any process or application. Researchers proposed two different ways to detect ransomware using machine learning: host-based and network-based. In case of host-based analyzing approach file system activity, API calls, registry key operations, energy consumption patterns and other features are monitored. In network-based approach, malicious and benign traffic samples/logs are analyzed; for example, destination and source IP address, protocol type, source and destination port number, the total number of bytes and packets per conversation. Also, protection solutions can be divided into early-stage ransomware detection (before encryption) and post encryption detection, which are not such relevant.
The advantage of the ML-based protection approach over signature-based methods is that it is able to detect zero-day** **attacks using anomaly detection methods. In “Zero-day aware decision fusion-based model for crypto-ransomware early detection” authors used group of one-class SVM models which were trained on benign programs. The results of this classifier were integrated using the majority voting method. In “Automated Analysis Approach for the Detection of High Survivable Ransomware” researchers proposed a framework for the behavioral-based dynamic analysis of high survivable ransomware (HSR) with integrated valuable feature sets. Term Frequency-Inverse document frequency (TF-IDF) was employed to select the most useful features from the analyzed samples. Support Vector Machine (SVM) and Artificial Neural Network (ANN) were utilized to develop and implement a machine learning-based detection model able to recognize certain behavioral traits of high survivable ransomware attacks.
The main challenges regarding ransomware area:
- irrelevant and redundant system calls, obfuscation/ packing technique usage to bypass ML model detection can be used;
- the ransomware detection systems are platform-dependent;
- diversity of ransomware families;
- datasets used to train are synthetic and extracted from specific sources, i.e., pseudo-real world events;
- not all the detection studies available in the literature are practical to implement.
Open datasets:
- Ransomware Dataset RISSP group
- Ransomware bitcoin datasets
- ISOT Ransomware dataset
- Microsoft Malware Classification Challenge (BIG 2015)
ML projects ideas:
- host-based ransomware detection using static/dynamic/hybrid features;
- ransomware by network traffic analysis, network traffic clusterization;
- ransomware/normal malware/benign applications classification;
- ransomware family classification.
Adversarial attacks and Machine Learning Apps security
Traditional antivirus solutions are only effective half of the time, it use signature-based methods and heuristics to search through already seen attacks. Attackers have learned to overcome that protection using polymorphic malwares and obfuscation techniques. Next-generation antivirus (NGAV) programs hit the market, NGAV uses artificial intelligence, behavioural patters and predictive modeling techniques to identify malware and malicious behavior in advance. Thus, adversarial machine learning attacks enter the scene, here is the math formulation of the problem:
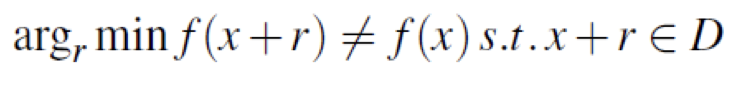
Minimization problem for adversarial examples generationThe input sample x, correctly classified by the classifier f, is perturbed with r such that the resulting adversarial example, x + r, remains in the input domain D but is assigned a different label than x.
As can be seen from the problem formalization, such attacks are easy to carry out in the field of computer vision, one can simply add noise to the input image in the direction of corresponding gradient, so that it will be misclassified. This fact is well illustrated by fast gradient sign method.
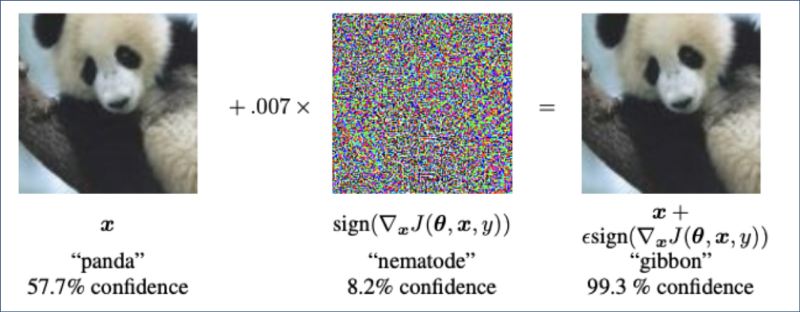
Fast gradient sign method, source: https://www.tensorflow.org/tutorials/generative/adversarial_fgsm
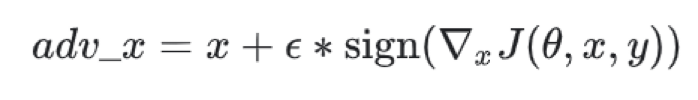
In the computer vision domain, the adversary can change every pixel’s colour (to a different valid colour) without creating an “invalid picture” as part of the attack. However, in the cyber security domain, modifying an API call (e.g. replacing WriteFile() call with ReadFile() ) might cause executable to perform differently or even crash. Network packages perturbation in order to evade network intrusion detection module is also challenging task. Small changes not perceived by human eye are not possible in cybersecurity domain. However, some transparency in the process of machine learning makes it easier for hackers to make attacks against ML modules. An example would be the use of transfer learning, where ML engineers utilize common pre-trained model architectures or phishing URL detection task where common NLP features are employed. In that case, it would be gray-box attack, when hacker has partial information about ML model training process. This review could be a good starting point to explore adversarial attacks in various cybersecurity areas, its types and purposes, as well as defense methods.
ML projects ideas:
- generate adversarial examples using GAN and test your ML model robustness using these examples;
- deepfake detection model like MesoNet/ MesoInception.
Further reading:
Internet of Things (IoT) systems:
- A Survey of Machine and Deep Learning Methods for Internet of Things (IoT) Security
- N-BaIoT: Network-based Detection of IoT Botnet Attacks Using Deep Autoencoders
- Deep Learning for Detection of Routing Attacks in the Internet of Thing
- OWASP IoT Top 10 based Attack Dataset for Machine Learning
- Detecting Malware in Cyberphysical Systems Using Machine Learning: a Survey
Advanced Persistent Threat (APT):
- A New Proposal on the Advanced Persistent Threat: A Survey
- A Survey of Machine Learning Techniques Used to Combat Against the Advanced Persistent Threat
- DMAPT: Study of Data Mining and Machine Learning Techniques in Advanced Persistent Threat Attribution and Detection
- Detection of advanced persistent threat using machine-learning correlation analysis
Fraud detection:
- Types of fraud
- Deep Learning for Anomaly Detection: A Review
- Credit card fraud detection using machine learning: A survey
Targeted ransomwares:
- A Survey on Machine Learning-Based Ransomware Detection
- Ransomware Detection Using the Dynamic Analysis and Machine Learning: A Survey and Research Directions
- A Survey on Detection Techniques for Cryptographic Ransomware
- Automated Analysis Approach for the Detection of High Survivable Ransomware
Adversarial attacks and Machine Learning Apps security:
- Adversarial Machine Learning Attacks and Defense Methods in the Cyber Security Domain
- Adversarial Attacks and Defenses in Deep Learning
- Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey
- Black-box Adversarial Attacks Against Deep Learning Based Malware Binaries Detection with GAN
- AT-GAN: A Generative Attack Model for Adversarial Transferring on Generative Adversarial Net