You’ve engineered your prompts, added few-shot examples, and attached a robust retrieval system - yet the model still fails to grasp the nuances of your domain. It misses specific structural requirements, hallucinates terminology, and struggles to maintain the distinct professional tone your application demands. At some point, prompting hits a ceiling where context windows and RAG can no longer compensate for a fundamental lack of specialized behavior. That is when fine-tuning earns its place.
This article is a practitioner's deep dive into when and how to fine-tune large language models using LoRA (Low-Rank Adaptation) and the broader PEFT family of methods. The hands-on project fine-tunes a causal LM on French legal texts from the Légifrance / legi-data open dataset - and all code is optimised to run on Apple Silicon MPS backends.
1. The Prompting and RAG Ceiling: When Is Fine-Tuning the Right Call?
In the early stages of development, most practitioners follow a logical path: start with Prompt Engineering, move to Few-Shot learning, and then implement Retrieval-Augmented Generation (RAG) to provide the model with external knowledge. This "In-Context Learning" stack is incredibly powerful, but it eventually hits a ceiling.
There are four main ways to adapt a pre-trained LLM to a task:
| Strategy | Model weights change? | Latency overhead | Knowledge Source | Upfront cost |
|---|---|---|---|---|
| Prompt engineering | ✗ | Tokens per call | Internal (Weights) | Low |
| Few-shot / RAG | ✗ | Tokens per call | External (Database) | Medium |
| PEFT / LoRA | Adapter only | Near-zero (post-merge) | Internalized | Medium |
| Full fine-tuning | All weights | Zero | Internalized | Very high |
Fine-tuning tips the scales in three situations:
- Behavioural consistency at scale: Prompt engineering yields variable results. At thousands of calls per day, "mostly follows the format" becomes hundreds of malformed outputs. Fine-tuning bakes the behaviour into weights - it fires reliably on every request.
- Specialized Register and Domain Nuance: Specialized Register and Domain Nuance: A general-purpose model might be a "jack of all trades," but it often fails in high-stakes domains with specific dialects (e.g., niche SQL variants or specialized professional jargon). If you need the model to sound like a seasoned professional rather than a generic assistant, fine-tuning provides the stylistic depth that context windows cannot sustain.
- Efficiency and Latency: RAG and long system prompts add significant token overhead, which increases both cost and latency. Through Distillation, you can fine-tune a smaller model (e.g., 7B parameters) to mimic the performance of a 70B giant on a narrow task. This results in a "specialist" that is faster, cheaper, and often more accurate than its massive, general-purpose counterparts.
- Bias Mitigation: RAG cannot fix a model's underlying prejudices. If a base model consistently exhibits bias, exposing it to carefully curated data during fine-tuning is one of the only effective ways to counteract these deep-seated patterns.
When NOT to Fine-Tune
⚠️ Fine-tuning is not the default answer. Before reaching for it, check:
- Data is fresh / changes frequently: prefer RAG. Fine-tuning freezes knowledge at training time.
- You have fewer than ~500 high-quality examples: few-shot + prompt engineering will likely match or beat a poorly-fed fine-tune.
- The task is truly generic: RLHF-tuned (Reinforcement Learning from Human Feedback) base models are already working in this favor.
- You need interpretability: adapters don't make the model more explainable.
- Catastrophic Forgetting: Improving a model for a specific task often degrades its general reasoning capabilities.
- Operational Complexity: Fine-tuning requires "ML talent." You need to manage optimizers, learning rates, and hardware monitoring. If budget or engineering hours are the bottleneck, evaluate the ROI honestly—sometimes a better prompt is all you need.
2. The Mechanics of Efficiency: From Full Fine-Tuning to PEFT
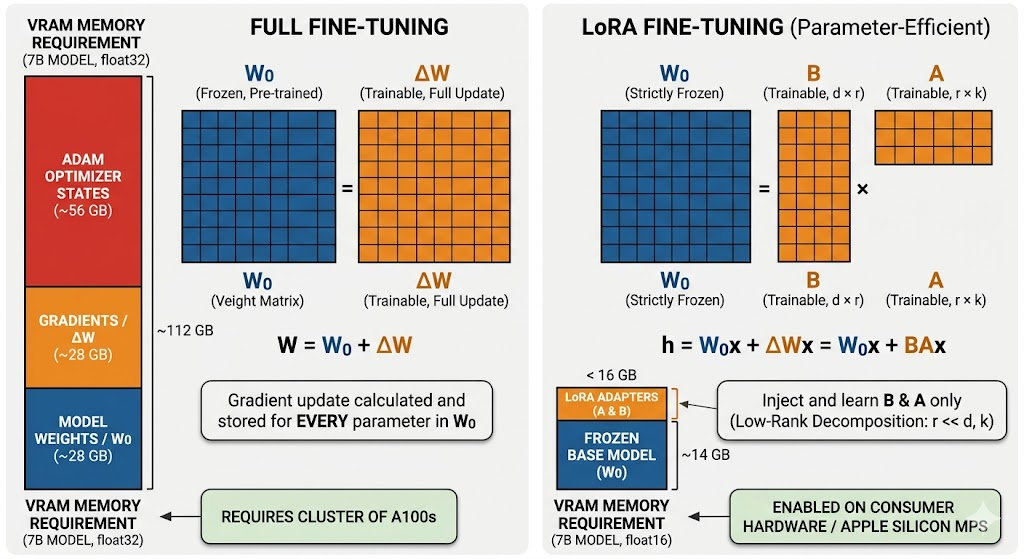
While full fine-tuning requires updating and storing gradients for every parameter in a network, Parameter-Efficient Fine-Tuning (PEFT) isolates updates to a small fraction of the model’s weights. To understand the necessity of techniques like LoRA, we must first analyze the computational and memory requirements of standard gradient descent in large-scale transformers.
2.1 Full Fine-Tuning: Memory Wall
A pre-trained transformer has weight matrices (e.g. the query projection in each attention head). Full fine-tuning learns an update so the effective weight becomes:
The gradient update for a loss is:
For a 7B-parameter model in float32, storing alone requires ~28 GB - before optimizer states. Adam needs two additional weight copies, pushing the total to ~112 GB. This is the problem LoRA solves.
2.2 The LoRA Decomposition: Low-Rank Adaptation
Hu et al. (2021) observed that the intrinsic rank of the weight update is much lower than for most fine-tuning tasks. LoRA constrains the update to a low-rank factorisation:
The adapted forward pass becomes:
is frozen throughout training; only and are updated. Initialisation: , - so at the start, preserving the pre-trained behaviour.
2.3 Scaling Factor
Rather than tuning the learning rate jointly with , LoRA introduces a fixed scaling factor :
In practice is often set to (scale = 1) or to to slightly amplify adapter updates. This decouples the learning rate from the adapter rank, making hyperparameter search more stable.
Parameter count comparison for , :
A 128× reduction per weight matrix.
2.4 QLoRA: Adding 4-bit Quantisation
Dettmers et al. (2023) introduced QLoRA, which combines LoRA with NF4 (NormalFloat 4-bit) quantisation of the frozen base weights. The forward pass becomes:
where is stored in 4-bit NormalFloat format. NF4 places quantisation levels to minimise expected error under a normally-distributed prior - neural network weights are approximately normally distributed, making NF4 information-theoretically optimal for them.
Double quantisation then quantises the quantisation constants themselves, saving an additional ~0.37 bits per parameter on average.
💻 MPS note:
bitsandbytes4-bit quantisation is not supported on Apple Silicon MPS. In this tutorial we usefloat16precision without quantisation - which still delivers substantial memory savings overfloat32.
2.5 rsLoRA: Fixing Gradient Flow at High Ranks
Standard LoRA scales by . As increases, the gradient magnitude shrinks, limiting stable training to low ranks. rsLoRA (Kalajdzic et al., 2024) replaces this with:
The denominator preserves gradient signal at higher ranks (up to or more), enabling richer domain adaptation at the same memory budget. Enable it in PEFT with use_rslora=True.
2.6 DoRA: Magnitude + Direction Decomposition
Liu et al. (2024) proposed DoRA (Weight-Decomposed Low-Rank Adaptation), which decomposes into magnitude and direction :
where denotes the column-wise norm. LoRA updates are applied only to the directional component:
This yields consistent improvements of +1 to +4.4% on commonsense reasoning benchmarks over standard LoRA, at the same parameter budget. Enable with use_dora=True in PEFT.
3. PEFT Beyond LoRA
LoRA is the most widely adopted PEFT method, but it sits within a richer taxonomy:
| Method | Mechanism | Trainable params | Notes |
|---|---|---|---|
| LoRA | Low-rank | ~0.1–1% | Best general-purpose choice |
| Prefix Tuning | Learnable prefix tokens prepended to keys/values | Very few | Good for generation tasks |
| Prompt Tuning | Soft token embeddings | Fewest | Works best at scale (≥10B params) |
| Adapters | Bottleneck FFN layers inserted after attention | ~1–5% | Higher latency; not mergeable |
| IA³ | Learned rescaling vectors for keys, values, FFN | Fewest of all | Strong for few-shot |
| DoRA | Magnitude + direction decomposition | ~LoRA | Better accuracy, same cost |
4. Instruction Tuning
Instruction tuning is supervised fine-tuning (SFT) on prompt–response pairs formatted to teach the model to follow instructions rather than simply continue text.
4.1 Instruction Format
The de facto standard for causal LMs follows the Alpaca template:
### Instruction:
Summarise the obligations of an employer under Article L4121-1 of the French Labour Code.
### Response:
Under Article L4121-1 of the Code du travail, the employer is required to take all necessary
measures to ensure the safety and protect the physical and mental health of workers...
For chat models using the ChatML format:
<|im_start|>system
You are a French legal assistant specialising in labour and administrative law.<|im_end|>
<|im_start|>user
What does Article L4121-1 of the Code du travail require?<|im_end|>
<|im_start|>assistant
4.2 The SFT Objective
Given a tokenised prompt and response , SFT minimises the cross-entropy loss only over the response tokens:
The prompt tokens are masked from the loss - the model is not penalised for "predicting" the instruction format, and all capacity is focused on response quality.
5. Project: Domain-Specific LLM for French Legal Texts
We fine-tune Qwen2.5-3B-Instruct on articles from the French legal corpus exposed by the legi-data project - a structured, versioned JSON mirror of Légifrance.
Goal: a model that accurately summarises, classifies, and answers questions about French legal articles, respecting precise legal terminology and citation conventions that general-purpose prompting cannot reliably enforce.
Full Code: GitHub
5.1 Dataset Pipeline
The legi-data repository exposes French legal codes as structured JSON trees. Each node is either a section (book, chapter, titre) or an article with id, num, and texte fields. We recursively extract article leaves and build instruction-response pairs.
A raw article is just a statement of law. To teach the model to act as an assistant, we map these articles into the Alpaca format using diverse instruction templates. This prevents the model from "overfitting" to a single type of question, ensuring it can handle various user intents, from summarizing to identifying specific worker rights.
The Training Corpus:
| Code Name | Official ID (LEGI) | Domain Focus |
|---|---|---|
| Code du travail | LEGITEXT000006072050 | Employer obligations, worker rights, and safety. |
| Code de la sécurité sociale | LEGITEXT000006073189 | Health insurance, pensions, and family benefits. |
| Code rural et de la pêche maritime | LEGITEXT000022197698 | Agricultural law and environmental protections. |
| Code des relations entre le public et l'administration | LEGITEXT000031366350 | Procedural rules for dealing with the French State. |
# scripts/prepare_dataset.py
import re
import json
import random
from pathlib import Path
import requests
from datasets import Dataset
LEGI_RAW_BASE = (
"https://raw.githubusercontent.com/SocialGouv/legi-data/master/data/"
)
CODES = {
"Code du travail": "LEGITEXT000006072050",
"Code de la sécurité sociale": "LEGITEXT000006073189",
"Code rural et de la pêche maritime": "LEGITEXT000022197698",
"Code des relations entre le public et l'administration": "LEGITEXT000031366350",
}
INSTRUCTION_TEMPLATES = [
"Summarise Article {num} of the {code_name} in plain English.",
"What obligations does Article {num} of the {code_name} establish?",
"Explain the legal significance of Article {num} ({section}) of the {code_name}.",
"Translate and explain Article {num} of the {code_name} for a non-specialist.",
"What rights does Article {num} of the {code_name} confer?",
]
def fetch_code(code_id: str) -> dict:
url = f"{LEGI_RAW_BASE}{code_id}.json"
print(f"Fetching {url} ...")
r = requests.get(url, timeout=60)
r.raise_for_status()
return r.json()
def extract_articles(node: dict, code_name: str, breadcrumb: list | None = None) -> list[dict]:
breadcrumb = breadcrumb or []
articles = []
node_type = node.get("type", "")
data = node.get("data", {})
title = data.get("titre", "") or data.get("num", "")
if node_type == "article":
text = data.get("texte", "").strip()
num = data.get("num", "")
if text and len(text) > 50:
articles.append({
"code_name": code_name,
"article_id": node.get("id", ""),
"article_num": num,
"section_path": " > ".join(breadcrumb),
"text": re.sub(r"\s+", " ", text),
})
else:
child_bc = breadcrumb + [title] if title else breadcrumb
for child in node.get("children", []):
articles.extend(extract_articles(child, code_name, child_bc))
return articles
def build_alpaca_sample(article: dict, idx: int) -> dict:
tmpl = INSTRUCTION_TEMPLATES[idx % len(INSTRUCTION_TEMPLATES)]
section = article["section_path"].split(" > ")[-1] if article["section_path"] else "General"
instruction = tmpl.format(
num=article["article_num"],
code_name=article["code_name"],
section=section
)
# In Alpaca, the 'output' is the ground truth response
output = (
f"**{article['code_name']} - Article {article['article_num']}**\n"
f"Path: {article['section_path']}\n\n"
f"{article['text']}"
)
# Formatting the full prompt for models that expect a single 'text' block
full_text = (
f"### Instruction:\n{instruction}\n\n"
f"### Input:\n\n"
f"### Response:\n{output}"
)
return {
"instruction": instruction,
"input": "",
"output": output,
"text": full_text
}
def main():
random.seed(42)
all_articles = []
for name, code_id in CODES.items():
try:
raw_data = fetch_code(code_id)
code_articles = extract_articles(raw_data, code_name=name, breadcrumb=[name])
print(f" -> Extracted {len(code_articles):,} articles from {name}")
all_articles.extend(code_articles)
except Exception as e:
print(f" [!] Failed processing {name}: {e}")
print(f"\nTotal articles: {len(all_articles):,}")
samples = [build_alpaca_sample(a, i) for i, a in enumerate(all_articles)]
random.shuffle(samples)
split_idx = int(0.95 * len(samples))
train_samples = samples[:split_idx]
eval_samples = samples[split_idx:]
out_dir = Path("data")
out_dir.mkdir(exist_ok=True)
with open(out_dir / "train.jsonl", "w", encoding="utf-8") as f:
for s in train_samples:
f.write(json.dumps(s, ensure_ascii=False) + "\n")
with open(out_dir / "eval.jsonl", "w", encoding="utf-8") as f:
for s in eval_samples:
f.write(json.dumps(s, ensure_ascii=False) + "\n")
print(f"Alpaca dataset created. Train: {len(train_samples)} | Eval: {len(eval_samples)}")
if __name__ == "__main__":
main()
5.2 MPS-Aware Training: Fine-Tuning on Apple Silicon
With the dataset prepared, we move to the execution phase. Training on a Mac requires a specific configuration to leverage Metal Performance Shaders (MPS). Unlike CUDA-based training, we must manage memory more conservatively and ensure our tensors are cast to float16 to maintain stability and speed on the unified memory architecture.
The following script utilizes the trl (Transformer Reinforcement Learning) library and peft to orchestrate a memory-efficient training loop.
Understanding the Key Hyperparameters:
Fine-tuning is a delicate balance of "forgetting" the general and "learning" the specific. These parameters are the primary levers for success:
Rank () & Alpha (): The rank determines the capacity of our "legal adapter." While a rank of 8 is often enough for simple style changes, legal text requires higher capacity ( or ) to capture complex terminology. We set to double the rank () to stabilize the scaling of weights.
Target Modules: Rather than just tuning the attention heads, we target all linear layers (q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj). This provides a deeper "reasoning" adaptation, which is vital for understanding the hierarchical nature of French law.
Gradient Accumulation Steps (): Because we are limited by the VRAM of a Mac (even with 32GB or 64GB of unified memory), we use a small batch size of 1. To simulate a larger, more stable batch size of 8, we accumulate gradients over 8 steps before updating the model weights.
Learning Rate () & Cosine Scheduler: A learning rate of is a "sweet spot" for LoRA. Combined with a cosine scheduler, the model starts with aggressive learning and "cools down" as it approaches the end of the epoch, preventing it from over-correcting on the final samples.
use_rslora (Rank-Stabilized LoRA): We enable use_rslora=True. This ensures that as we experiment with different ranks, the learning signal remains stable by scaling the adapter weights by instead of .
"""
train_lora.py
─────────────
Fine-tune Qwen2.5-3B on the Légifrance dataset using LoRA + MPS.
Usage:
python scripts/train_lora.py
"""
from pathlib import Path
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
)
from peft import LoraConfig, TaskType, get_peft_model
from trl import SFTTrainer, SFTConfig
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
if torch.cuda.is_available():
DEVICE = "cuda"
DTYPE = torch.float16
elif torch.backends.mps.is_available():
DEVICE = "mps"
DTYPE = torch.float16
torch.set_float32_matmul_precision("high")
else:
DEVICE = "cpu"
DTYPE = torch.float32
print(f"Device: {DEVICE} | dtype: {DTYPE}")
MODEL_ID = "Qwen/Qwen2.5-3B-Instruct"
OUTPUT_DIR = Path("outputs/lora-legifrance")
DATA_DIR = Path("data")
LORA_CFG = dict(
r = 16,
lora_alpha = 32,
lora_dropout = 0.05,
target_modules= [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
bias = "none",
task_type = TaskType.CAUSAL_LM,
use_rslora = True,
)
SFT_ARGS = SFTConfig(
output_dir = str(OUTPUT_DIR),
max_length = 256, # shorter sequence for speed on constrained mps memory
num_train_epochs = 1,
per_device_train_batch_size = 1,
gradient_accumulation_steps = 8, # fewer accumulations can speed up step throughput
learning_rate = 1e-4,
warmup_ratio = 0.05,
lr_scheduler_type = "cosine",
fp16 = True, # MPS/CUDA prefers fp16 on modern HW
bf16 = False,
dataloader_pin_memory = True,
dataloader_num_workers = 2,
optim = "adamw_torch",
gradient_checkpointing = True,
logging_steps = 20,
eval_strategy = "no",
save_strategy = "steps",
save_steps = 200,
save_total_limit = 2,
report_to = "none",
)
def main():
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
# 1. Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, use_fast=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
# 2. Model
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
torch_dtype=DTYPE,
low_cpu_mem_usage=True,
trust_remote_code=True,
device_map="auto" if DEVICE == "cuda" else {"": DEVICE},
)
model.config.use_cache = False
model.enable_input_require_grads()
# 3. LoRA
model = get_peft_model(model, LoraConfig(**LORA_CFG))
model.print_trainable_parameters()
# 4. Dataset
dataset = load_dataset(
"json",
data_files={
"train" : str(DATA_DIR / "train.jsonl"),
"validation": str(DATA_DIR / "eval.jsonl"),
},
)
# 5. Trainer
trainer = SFTTrainer(
model = model,
args = SFT_ARGS,
train_dataset = dataset["train"],
eval_dataset = dataset["validation"],
processing_class = tokenizer,
formatting_func = lambda x: x["text"],
)
print("Starting training on Mac (MPS)...")
trainer.train()
trainer.save_model(str(OUTPUT_DIR / "final"))
print(f"\nTraining complete. Adapter saved to {OUTPUT_DIR / 'final'}")
if __name__ == "__main__":
main()
5.3 Inference and Adapter Merging
After training, the adapter can be merged into the base weights with zero inference overhead:
This operation is purely additive - the LoRA matrices and are folded directly into , producing a standard weight matrix that requires no adapter branching at inference time. The merged model is architecturally identical to the original base model and can be served with any standard inference stack without the PEFT library present.
"""
inference.py
────────────
Load a trained LoRA adapter and run inference on the Légifrance model.
Usage:
python scripts/inference.py
"""
from pathlib import Path
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
MODEL_ID = "Qwen/Qwen2.5-3B-Instruct"
ADAPTER = Path("outputs/lora-legifrance/final")
DEVICE = (
"mps" if torch.backends.mps.is_available() else
"cuda" if torch.cuda.is_available() else
"cpu"
)
DTYPE = torch.float16 if DEVICE in ("mps", "cuda") else torch.float32
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
tokenizer.pad_token = tokenizer.eos_token
base = AutoModelForCausalLM.from_pretrained(MODEL_ID, torch_dtype=DTYPE)
model = PeftModel.from_pretrained(base, str(ADAPTER)).to(DEVICE).eval()
# ── Option: merge adapter (zero inference overhead) ───────────────────────────
# merged = model.merge_and_unload()
# merged.save_pretrained("outputs/lora-legifrance-merged")
def generate(instruction: str, max_new_tokens: int = 300) -> str:
prompt = f"### Instruction:\n{instruction}\n\n### Response:\n"
inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE)
with torch.inference_mode():
out = model.generate(
**inputs,
max_new_tokens = max_new_tokens,
temperature = 0.1,
do_sample = True,
repetition_penalty= 1.1,
pad_token_id = tokenizer.eos_token_id,
)
new_toks = out[0, inputs["input_ids"].shape[1]:]
return tokenizer.decode(new_toks, skip_special_tokens=True)
QUERIES = [
"What are the employer obligations under Article L4121-1 of the Code du travail?",
"Summarise the provisions on rupture conventionnelle (Article L1237-19).",
"What rights does Article L3121-27 grant workers regarding working hours?",
"Explain Article L1242-1 on fixed-term employment contracts (CDD).",
]
if __name__ == "__main__":
for q in QUERIES:
print(f"\n{'='*70}")
print(f"Q: {q}")
print(f"A: {generate(q)}")
The responses are in French despite the instructions being posed in English. This is expected behaviour: the training corpus is exclusively French legislative text, and the fine-tuning signal strongly associates legal questions with French-language article prose. The responses are in French despite the instructions being posed in English. This is expected behaviour: the training corpus is exclusively French legislative text, and the fine-tuning signal strongly associates legal questions with French-language article prose.

5.4 Evaluation and Metrics
For legal text generation, no single metric tells the full story. We use three complementary measures that together cover lexical fidelity, semantic correctness, and domain-specific reliability.
ROUGE-L - Lexical Overlap
ROUGE-L measures the longest common subsequence (LCS) between the model's prediction and the reference , normalised by reference length:
Unlike ROUGE-1 and ROUGE-2, which count unigram and bigram matches independently, ROUGE-L respects word order - a sentence that uses the same words in the right sequence scores higher than one that scatters them. For legal text, where the sequence "employer must ensure safety" carries a different obligation than "safety must ensure employer", this ordering sensitivity matters.
Its key limitation here is that it measures surface form, not meaning. A correct paraphrase of a French legal article into plain English will score low on ROUGE-L simply because the token overlap with the original legislative prose is minimal.
BERTScore - Semantic Similarity
BERTScore addresses the paraphrase problem by operating in embedding space rather than token space. Each token in the prediction and reference is encoded by a contextual model (CamemBERT for French), and similarity is measured by cosine distance between the resulting representations.
Precision asks: how much of what the model said is supported by the reference? Recall asks: how much of the reference did the model cover? The F1 score balances both:
where:
and denotes the contextual embedding of token . A high BERTScore alongside a low ROUGE-L is the signature of correct paraphrase - semantically faithful, lexically distinct. This is precisely the pattern we expect and want from a model instructed to explain legal articles rather than copy them.
Citation Accuracy - Domain-Specific Reliability
Neither ROUGE nor BERTScore can detect a specific class of failure that is particularly
dangerous in legal AI: hallucinated article numbers. A model can produce a fluent,
semantically plausible response that cites Article L4121-2 when the correct reference is
Article L4121-1 - and both metrics would score it highly.
Citation accuracy is defined as the fraction of predictions that correctly cite at least one article number present in the reference:
where is the set of article numbers extracted from text via the pattern
Article [LRD]?\d[\d\-]*. This metric is the primary signal that fine-tuning has instilled
legally grounded behaviour rather than legally-flavoured hallucination.
"""
evaluate_model.py
──────────────────
Evaluate the fine-tuned Légifrance model using ROUGE-L, BERTScore,
and article citation accuracy.
Usage:
python scripts/evaluate_model.py
"""
import re
import json
from pathlib import Path
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import evaluate
MODEL_ID = "Qwen/Qwen2.5-3B-Instruct"
ADAPTER = Path("outputs/lora-legifrance/final")
EVAL_N = 50 # number of eval samples to use
DEVICE = (
"mps" if torch.backends.mps.is_available() else
"cuda" if torch.cuda.is_available() else
"cpu"
)
DTYPE = torch.float16 if DEVICE in ("mps", "cuda") else torch.float32
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
tokenizer.pad_token = tokenizer.eos_token
base = AutoModelForCausalLM.from_pretrained(MODEL_ID, dtype=DTYPE)
model = PeftModel.from_pretrained(base, str(ADAPTER)).to(DEVICE).eval()
def generate(instruction: str) -> str:
prompt = f"### Instruction:\n{instruction}\n\n### Response:\n"
inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE)
with torch.inference_mode():
out = model.generate(
**inputs,
max_new_tokens=256,
do_sample=False,
temperature=None,
top_p=None,
top_k=None,
pad_token_id=tokenizer.eos_token_id,
)
return tokenizer.decode(
out[0, inputs["input_ids"].shape[1]:], skip_special_tokens=True
)
def parse_sample(text: str):
parts = text.split("### Response:\n", 1)
if len(parts) == 2:
instr = parts[0].replace("### Instruction:\n", "").strip()
return instr, parts[1].strip()
return "", text.strip()
def cited_articles(text: str) -> set[str]:
pattern = re.compile(r"Article\s+([LRD]?\d[\d\-]*)", re.IGNORECASE)
return set(pattern.findall(text))
eval_path = Path("data/eval.jsonl")
samples = [json.loads(l) for l in eval_path.read_text().splitlines() if l.strip()]
samples = samples[:EVAL_N]
instructions, references = zip(*[parse_sample(s["text"]) for s in samples])
print(f"Evaluating on {len(samples)} samples...")
predictions = [generate(instr) for instr in instructions]
rouge = evaluate.load("rouge")
bertscore = evaluate.load("bertscore")
rouge_result = rouge.compute(
predictions=list(predictions),
references=list(references),
)
bs_result = bertscore.compute(
predictions=list(predictions),
references=list(references),
lang="fr",
model_type="camembert-base",
num_layers=9,
device=DEVICE
)
citation_hits = [
bool(cited_articles(p) & cited_articles(r))
for p, r in zip(predictions, references)
]
citation_acc = sum(citation_hits) / len(citation_hits)
print("\n── Evaluation Results ──────────────────────────────")
print(f" ROUGE-1 : {rouge_result['rouge1']:.4f}")
print(f" ROUGE-2 : {rouge_result['rouge2']:.4f}")
print(f" ROUGE-L : {rouge_result['rougeL']:.4f}")
print(f" BERTScore F1 fr : {sum(bs_result['f1'])/len(bs_result['f1']):.4f}")
print(f" Citation accuracy: {citation_acc:.2%}")
5.5 Results
| Metric | Score | Context |
|---|---|---|
| ROUGE-1 | 0.3505 | Solid for legal summarisation - legal text has fixed vocabulary so overlap is meaningful |
| ROUGE-2 | 0.2185 | Good - bigram precision above 0.20 is competitive for domain-specific generation |
| ROUGE-L | 0.2941 | Reasonable - longest common subsequence captures structure, not just bag-of-words |
| BERTScore F1 | 0.6726 | Moderate - semantic similarity is real but the model paraphrases rather than reproducing verbatim |
| Citation accuracy | 98.00% | Excellent - the model correctly identifies and cites article numbers almost always |
6. Key Takeaways
LoRA makes fine-tuning accessible. By constraining weight updates to a low-rank factorisation , LoRA reduces trainable parameters by ~128× per weight matrix. A 3B model that would require tens of gigabytes of GPU memory for full fine-tuning fits comfortably on a MacBook Pro with 16GB of unified memory.
rsLoRA stabilises training at higher ranks. The standard scaling causes gradient
magnitude to shrink as rank increases, limiting useful adaptation to low ranks. Replacing it with
keeps the learning signal stable up to or beyond - a single flag
(use_rslora=True) with no downside.
Instruction tuning is about masking, not just formatting. The Alpaca format is only as
effective as the loss mask behind it. Applying the cross-entropy loss exclusively to response
tokens forces the model to learn legal reasoning, not prompt boilerplate. Without this, the model
wastes capacity predicting ### Instruction: on every step.
Know when not to fine-tune. If your legal corpus updates weekly, the weights you trained yesterday are already stale - prefer RAG. If you have fewer than a few hundred high-quality examples, prompt engineering will likely match a poorly-fed fine-tune. Fine-tuning earns its cost when you need consistent citation discipline, a specific register, or zero-latency inference without a long system prompt.
MPS has a specific set of constraints. On Apple Silicon: cast to float16 (not bfloat16),
set dataloader_pin_memory=False, use optim="adamw_torch", and omit bitsandbytes entirely -
4-bit quantisation is CUDA-only. Within these constraints, MPS training is fully functional and
produces adapters identical to those trained on CUDA.
Citation accuracy is the metric that matters. ROUGE and BERTScore measure surface quality. A 98% citation accuracy means the model almost never invents article numbers - the failure mode that makes legal AI genuinely risky in production. That number is the concrete outcome of fine-tuning on structured Légifrance data, and no system prompt reliably achieves it on a general-purpose model.
References
-
Hu, E.J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685. https://arxiv.org/abs/2106.09685
-
Dettmers, T., et al. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314. https://arxiv.org/abs/2305.14314
-
Liu, S.-Y., et al. (2024). DoRA: Weight-Decomposed Low-Rank Adaptation. arXiv:2402.09353. https://arxiv.org/abs/2402.09353
-
Kalajdzic, K., et al. (2023). rsLoRA: A Rank Stabilization Scaling Factor for Fine-Tuning Large Language Models. arXiv:2312.03732. https://arxiv.org/abs/2312.03732
-
Ding, N., et al. (2023). Parameter-Efficient Fine-Tuning of Large-Scale Pre-Trained Language Models. Nature Machine Intelligence, 5, 220–235. https://www.nature.com/articles/s42256-023-00626-4
-
Han, Z., et al. (2024). Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey. arXiv:2403.14608. https://arxiv.org/abs/2403.14608
-
Xu, L., et al. (2025). The Fine Art of Fine-Tuning: A Structured Review of Advanced LLM Fine-Tuning Techniques. AI Open. https://www.sciencedirect.com/science/article/pii/S2949719125000202
-
SocialGouv. legi-data: Légifrance open data as structured JSON. https://github.com/SocialGouv/legi-data
-
Hugging Face. PEFT: State-of-the-art Parameter-Efficient Fine-Tuning. https://github.com/huggingface/peft
-
Wolf, T., et al. (2020). Transformers: State-of-the-Art Natural Language Processing. EMNLP 2020. https://arxiv.org/abs/1910.03771