Most websites use JavaScript (JS) to make dynamic content, which makes it a valuable attack vector against browsers, browser plug-ins, email clients, and other JS applications. Among common JS-based attacks are drive-by-download, cross-site scripting (XSS), cross-site request forgery (XSRF), and malvertising.
Most malicious JS code is obfuscated - a sequence of confusing code transformations that preserve functionality while hiding intent. Conventional antivirus signature-based methods struggle against zero-day obfuscated scripts.
Introduction
Most websites use JavaScript (JS) code to make dynamic content; thus, JS code becomes a valuable attack vector against browsers, browser plug-ins, email clients, and other JS applications. Among common JS-based attacks are drive-by-download, cross-site scripting (XSS), cross-site request forgery (XSRF), malvertising/malicious advertising, and others. Most of the malicious JS codes are obfuscated in order to hide what they are doing and to avoid being detected by signature-based security systems. In other words, the obfuscation technique is a sequence of confusing code transformations to compromise its understandability, but at the same time to save its functionality.

Example of randomization obfuscationConventional antiviruses and Intrusion Detection Systems (IDS) employ heuristic-based and signature-based methods to detect malicious JS code. But this analysis can be inefficient in case of zero-day attacks. Machine learning (ML) applications, which are currently being actively developed in various industries, have also found their place in cybersecurity. ML has shown its effectiveness against zero-based attacks. When it comes to detecting malicious JS code, there are different approaches from the field of Natural Language Processing (NLP), standard ML that uses tabular data, and deep learning models.
The input data for ML models will vary due to the fact that there are two methods to analyze the behavior of the program: static and dynamic code analysis. The static method analyzes the data without running the source code and is based on source code only. For instance, this can be archived by traversing the code Abstract Syntax Tree. In opposite, dynamic code analysis requires source code to be executed. In this post, we will consider only cases of static analysis.
In this article, we will look at some related work to get an idea of what researchers offer for obfuscated JS code detection. And also will consider the task of classifying benign /malicious JS code snippets using a combination of NLP features and the standard ML approaches.
Common Approaches to Feature JavaScript Code
In Detecting Obfuscated JavaScripts using Machine Learning the authors used a dataset of regular, minified, and obfuscated samples from a content delivery network jsDelivr, the Alexa top 500 websites, a set of malicious JavaScript samples from the Swiss Reporting and Analysis Centre for Information Assurance MELANI. Authors showed that it is possible to distinguish between obfuscated and non-obfuscated scripts with precision and recall around 99%. The following set of features has been used:
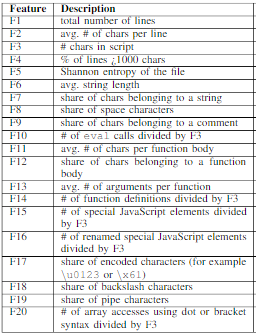
Static features for JavaScript snippets, source: Detecting Obfuscated JavaScripts using Machine Learning
The extracted set of feature vectors was utilized to train and evaluate three different classifiers: Linear Discriminant Analysis (LDA), Random Forest (RF), and Support Vector Machine (SVM).
In “A machine learning approach to detection of JavaScript-based attacks using AST features and paragraph vectors” the authors used another approach to extract features from JS codes. They employed Abstract Syntax Tree (AST) for code structure representation and used it as input to the Doc2Vec method. Drive-by-download data by Marionette for malicious JS codes and the JSUNPACK plus Alexa top 100 websites datasets for benign JS codes were used as datasets for training. For the purpose of constructing AST authors used Esprima, a syntactical and lexical analyzing tool.
While the previous approaches rely on lexical and syntactic features, the approach considered in “Malicious JavaScript Detection Based on Bidirectional LSTM Model” leverages semantic information. Along with AST features, the authors constructed the Program Dependency Graph (PDG) and generated JS code semantic slices which were transformed into numerical vectors. Then these vectors were fed into Bidirectional Long Short-Term Memory (BLSTM) neural network. BLSTM model showed performance with 97.71% accuracy and 98.29% F1-score.
| Approach | Description |
|---|---|
| Natural language | Treat JS as text: character statistics, entropies, special function counts |
| Lexical features | Regex + NLP methods (BoW, TF-IDF, Doc2Vec) |
| Syntactic features | Abstract Syntax Tree (AST) + NLP |
| Semantic features | AST → CFG → PDG → semantic slices → vectors |
Coding section: Classification of benign /malicious JS code
We use Approach 1 (natural language features) for simplicity. The dataset comes from Machine Learning for the Cybersecurity Cookbook.
import os
import re
import math
import warnings
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from tqdm import tqdm
from collections import Counter
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, cross_val_score
warnings.filterwarnings('ignore')
sns.set_theme(font_scale = 2)
SEED = 0
JS_DATA_DIR = "./JavascriptSamples"
OBFUSCATED_JS_DATA_DIR = "./JavascriptSamplesObfuscated"
Data downloading
filenames, scripts, labels = [], [], []
file_types_and_labels = [(JS_DATA_DIR, 0), (OBFUSCATED_JS_DATA_DIR, 1)]
for files_path, label in file_types_and_labels:
files = os.listdir(files_path)
for file in tqdm(files):
file_path = files_path + "/" + file
try:
with open(file_path, "r", encoding="utf8") as myfile:
df = myfile.read().replace("\n", "")
df = str(df)
filenames.append(file)
scripts.append(df)
labels.append(label)
except Exception as e:
print(e)
df = pd.DataFrame(data=filenames, columns=['js_filename'])
df['js'] = scripts
df['label'] = labels
df.head()

Data cleansing
# removing empty scripts
df = df[df['js'] != '']
# removing duplicates
df = df[~df["js"].isin(df["js"][df["js"].duplicated()])]
# Some obfuscated scripts I found in the legitimate JS samples folder, so let's change it label to 1
df["label"][df["js_filename"].apply(lambda x: True if 'obfuscated' in x else False)] = 1
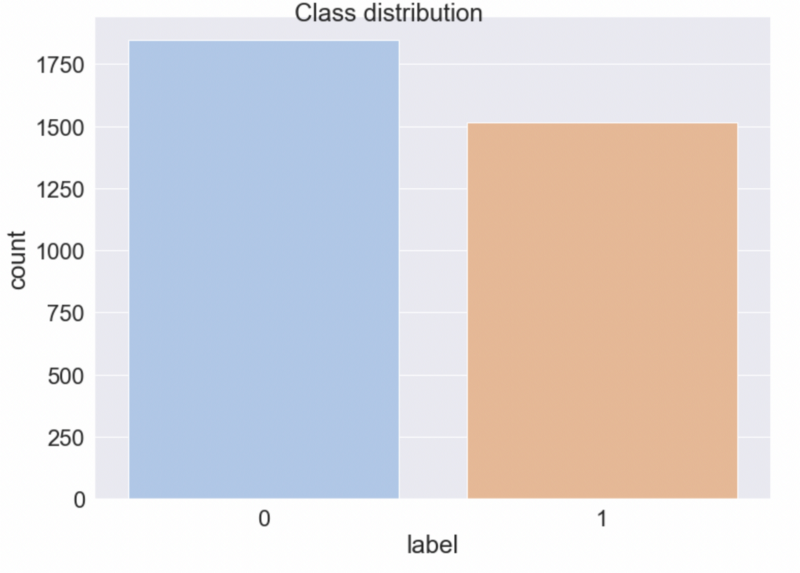
df.label.value_counts()
0-label — normal code, 1-label — obfuscated code

Feature engineering
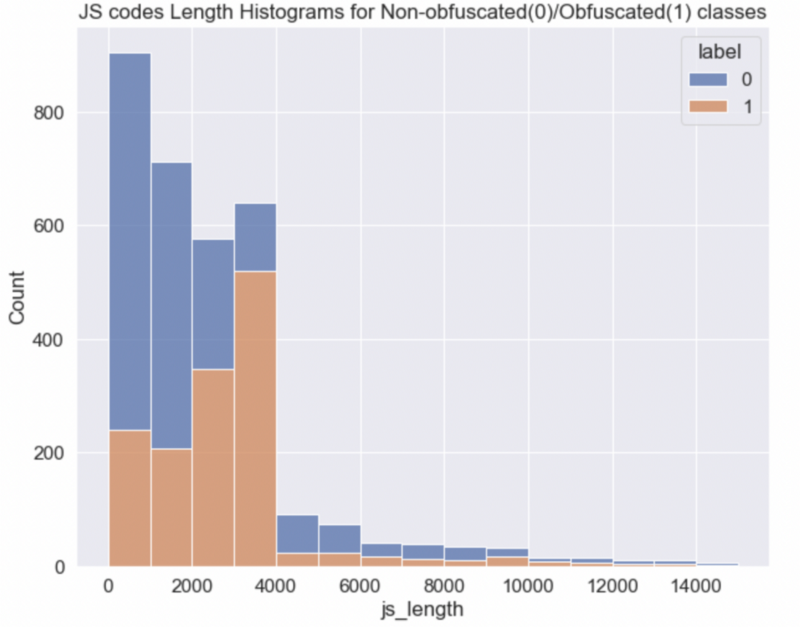
df['js_length'] = df.js.apply(lambda x: len(x))
df['num_spaces'] = df.js.apply(lambda x: x.count(' '))
df['num_parenthesis'] = df.js.apply(lambda x: (x.count('(') + x.count(')')))
df['num_slash'] = df.js.apply(lambda x: x.count('/'))
df['num_plus'] = df.js.apply(lambda x: x.count('+'))
df['num_point'] = df.js.apply(lambda x: x.count('.'))
df['num_comma'] = df.js.apply(lambda x: x.count(','))
df['num_semicolon'] = df.js.apply(lambda x: x.count(';'))
df['num_alpha'] = df.js.apply(lambda x: len(re.findall(re.compile(r"\w"),x)))
df['num_numeric'] = df.js.apply(lambda x: len(re.findall(re.compile(r"[0-9]"),x)))
df['ratio_spaces'] = df['num_spaces'] / df['js_length']
df['ratio_alpha'] = df['num_alpha'] / df['js_length']
df['ratio_numeric'] = df['num_numeric'] / df['js_length']
df['ratio_parenthesis'] = df['num_parenthesis'] / df['js_length']
df['ratio_slash'] = df['num_slash'] / df['js_length']
df['ratio_plus'] = df['num_plus'] / df['js_length']
df['ratio_point'] = df['num_point'] / df['js_length']
df['ratio_comma'] = df['num_comma'] / df['js_length']
df['ratio_semicolon'] = df['num_semicolon'] / df['js_length']
def entropy(s):
p, lns = Counter(s), float(len(s))
return -sum( count/lns * math.log(count/lns, 2) for count in p.values())
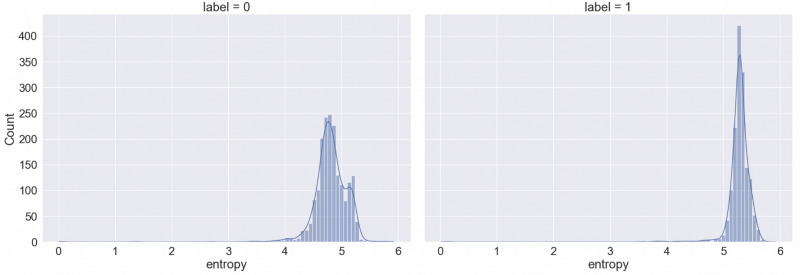
df['entropy'] = df.js.apply(lambda x: entropy(x))
print("Mean entropy for obfuscated js:", df['entropy'][df["label"] == 1].mean())
print("Mean entropy for non-obfuscated js:", df['entropy'][df["label"] == 0].mean())
For other features ideas I used the following list of JS functions that are frequently used in malicious JS codes:

Functions widely used in malicious JavaScript, source: Malicious JavaScript Detection Based on Bidirectional LSTM Model
# String Operation: substring(), charAt(), split(), concat(), slice(), substr()
df['num_string_oper'] = df.js.apply(lambda x: x.count('substring') +
x.count('charAt') +
x.count('split') +
x.count('concat') +
x.count('slice') +
x.count('substr'))
df['ratio_num_string_oper'] = df['num_string_oper'] / df['js_length']
print("Mean string operations for obfuscated js:", df['num_string_oper'][df["label"] == 1].mean())
print("Mean string operations for non-obfuscated js:", df['num_string_oper'][df["label"] == 0].mean())

# Encoding Operation: escape(), unescape(), string(), fromCharCode()
df['num_encoding_oper'] = df.js.apply(lambda x: x.count('escape') +
x.count('unescape') +
x.count('string') +
x.count('fromCharCode'))
df['ratio_num_encoding_oper'] = df['num_encoding_oper'] / df['js_length']
print("Mean encoding operations for obfuscated js:", df['num_encoding_oper'][df["label"] == 1].mean())
print("Mean encoding operations for non-obfuscated js:", df['num_encoding_oper'][df["label"] == 0].mean())

# URL Redirection: setTimeout(), location.reload(), location.replace(), document.URL(), document.location(), document.referrer()
df['num_url_redirection'] = df.js.apply(lambda x: x.count('setTimeout') +
x.count('location.reload') +
x.count('location.replace') +
x.count('document.URL') +
x.count('document.location') +
x.count('document.referrer'))
df['ratio_num_url_redirection'] = df['num_url_redirection'] / df['js_length']
print("Mean URL redirections for obfuscated js:", df['num_url_redirection'][df["label"] == 1].mean())
print("Mean URL redirections for non-obfuscated js:", df['num_url_redirection'][df["label"] == 0].mean())

# Specific Behaviors: eval(), setTime(), setInterval(), ActiveXObject(), createElement(), document.write(), document.writeln(), document.replaceChildren()
df['num_specific_func'] = df.js.apply(lambda x: x.count('eval') +
x.count('setTime') +
x.count('setInterval') +
x.count('ActiveXObject') +
x.count('createElement') +
x.count('document.write') +
x.count('document.writeln') +
x.count('document.replaceChildren'))
df['ratio_num_specific_func'] = df['num_specific_func'] / df['js_length']
print("Mean specific functions for obfuscated js:", df['num_specific_func'][df["label"] == 1].mean())
print("Mean specific functions for non-obfuscated js:", df['num_specific_func'][df["label"] == 0].mean())

Training a Random Forest Classifier
Train/test data split
X_train, X_test, y_train, y_test = train_test_split(df.iloc[:, 3:], df['label'],
stratify=df['label'],
test_size=0.2,
random_state=SEED)
Random Forest Model
clf=RandomForestClassifier(n_estimators=100, random_state=SEED)
clf.fit(X_train, y_train)
y_pred=clf.predict(X_test)
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
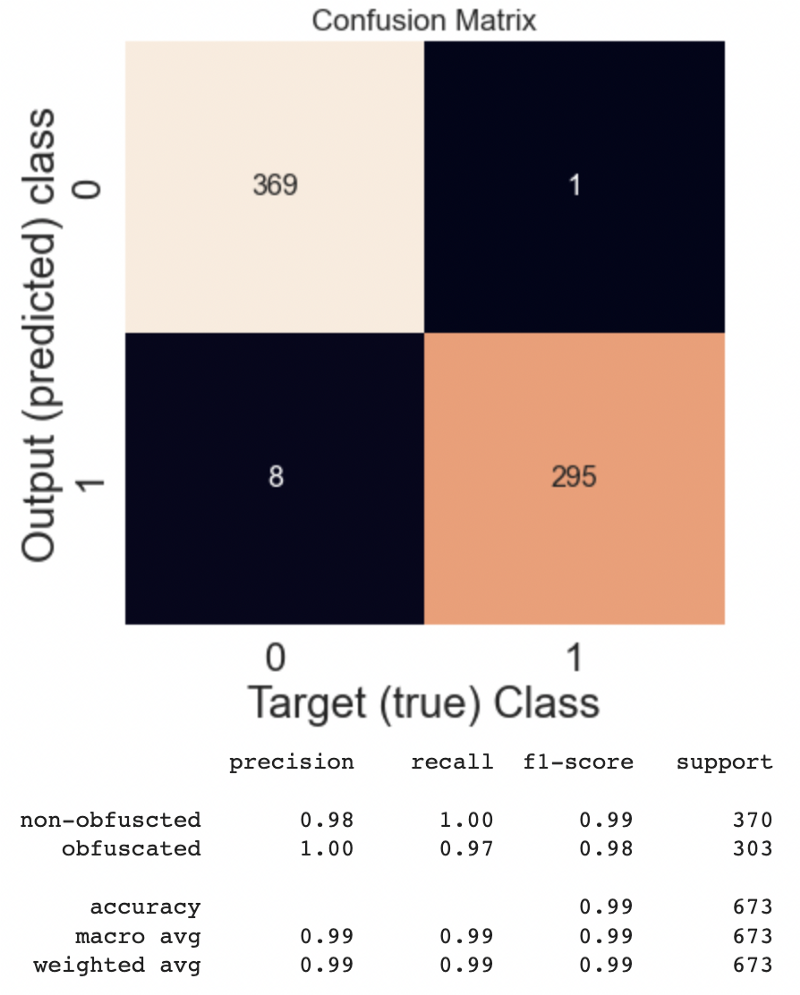
Metrics results
conf_mat = metrics.confusion_matrix(y_test, y_pred)
plt.subplots(figsize=(6,6))
sns.set(font_scale=1.4) # for label size
sns.heatmap(conf_mat, annot=True, fmt=".0f", annot_kws={"size": 16}, cbar=False) # font size
plt.xlabel('Target (true) Class'); plt.ylabel('Output (predicted) class'); plt.title('Confusion Matrix')
plt.show();
print(metrics.classification_report(y_test,
y_pred,
target_names=['non-obfuscted', 'obfuscated']))
Full code: GitHub
Further reading
[1] S. Aebersold et al., Detecting Obfuscated JavaScripts using Machine Learning (2016), ICIMP 2016: The Eleventh International Conference on Internet Monitoring and Protection
[2] S. Ndichu et al., A machine learning approach to detection of JavaScript-based attacks using AST features and paragraph vectors (2019), Applied Soft Computing
[3] A. Fass et al., JAST: Fully Syntactic Detection of Malicious (Obfuscated) JavaScript (2018), DIMVA
[4] X. Song et al., Malicious JavaScript Detection Based on Bidirectional LSTM Model (2020), Applied Sciences